Redisのクラスタリング¶
Note
Redis Cluster - (a pragmatic approach to distribution) (分散の実践的アプローチ)の日本語訳です。
New in version 2.2.
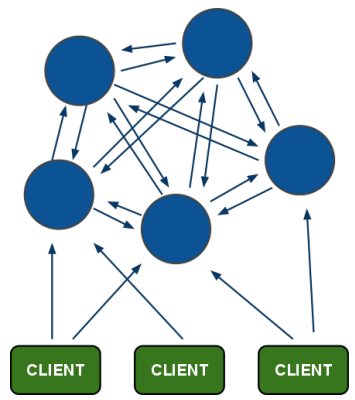
Redisでは、実際にクライアントと通信をするポート以外に、サービス用チャンネルを開いてすべてのノードはこのチャンネルを使って直接接続しあいます。TCPのベースのポート+4000番が使われるため、クライアント向けに6379番のポートを使用している場合には、10379番を使用します。ノード間の通信には、バンド幅と速度に最適化されたバイナリプロトコルを使用します。クライアントとの通信では通常はアスキープロトコルを使用しますが、いくつか変更があります。ノード同士は、クエリーをプロキシー(転送)することはありません。
ノード間の通信内容¶
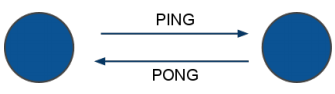
各ノードは、PING/PONGと同時に、自分が通信した上で判断した周辺ノード情報(Gossip/うわさ話)も一緒に送信します。
PING側¶
PING: 通信OK? 私は、XYZハッシュスロットのマスターです。設定は FF89X1JK です。
Gossip: 私が通信しあっている他のノードの情報はこれです:
- Aノードは私のpingに対して返事をくれたので、状態はOKだと思います。
- Bはアイドル中です。おそらく、Bノードでトラブルが発生していていますが、ACK信号を送って欲しいと思います。
PONG側¶
PONG: 通信OK? 私は、XYZハッシュスロットのマスターです。設定は FF89X1JK です。
Gossip: 私はランダムなノードに対しての情報をシェアしたいと考えています:
- CとDは時間内に返事をくれたので、正しい状態です。
- Bはアイドル状態です。おそらくダウンしています!
マスター・スレーブと冗長化¶
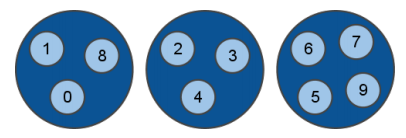
ノードはすべて接続されていて、すべて同じ機能を持っていますが、マスターノードと、スレーブノードという2種類のノードが存在します。
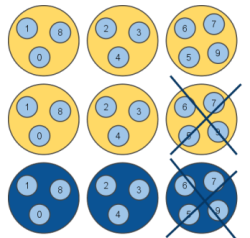
この図の例では、すべてのマスターノードごとに、2つのレプリカを作っています。この場合、どの2つのノードが落ちてもサービスは維持されます。最良のケースで、すべてのハッシュスロットごとに最低限1つのノードが生き残っていれば、動作は継続されます。
この状態について詳しく説明します。
- すべてのキーは、1つのインスタンスの中に保持されます。それにプラスして、書き込み命令を受け取らない、N個のレプリカの中にも保持されます。
- 訳不明
- Redisのレプリケーションを使用しているマスターノードとスレーブノードの情報をすでに知っています。
- すべての物理サーバは通常、スレーブとマスターを含む複数のノードを保持します。redis-tribクラスタマネージャプログラムは通常、なるべく異なる物理サーバにレプリカが配置されるように、マスターとスレーブを割り当てようとします。
クライアントからのリクエストの処理¶
低能なクライアントの場合¶
| 送信元 | 受信先 | 返信 | |
|---|---|---|---|
| クライアント | Aサーバ | GET foo | |
| Aサーバ | クライアント | -MOVED 8 192.168.5.21:6391 | |
| クライアント | Bサーバ | GET foo | |
| Bサーバ | クライアント | "bar" |
-MOVED 8... というエラーは、ハッシュスロット8は指定されたIP/ポートにあるという情報を返します。クライアントはこの情報を使って再度クエリーを発行する必要があります。
賢いクライアントの場合¶
| 送信元 | 受信先 | 返信 | |
|---|---|---|---|
| クライアント | Aサーバ | CLUSTER HINTS | |
| Aサーバ | クライアント | ハッシュスロットと、ノードの対応表 | |
| クライアント | Bサーバ | GET foo | |
| Bサーバ | クライアント | "bar" |
1ノードに対する接続だけを持っている(低能な)クライアントは、既存のクライアントコードを少し手直しするだけで動くようになります。リスト中のランダムなノードに対してコマンドを発行し、必要であれば(ハッシュスロットが別のノードにある場合)、クエリーを再発行します。
賢いクライアントは、多くのノードに対してコネクションと、ハッシュスロットとノードの対応表の情報を保持します。対応表が変更された場合には -MOVED エラーを受け取りますが、それ以外は1サーバ時と同じコストでアクセスできます。
この方式は、水平方向のスケーラビリティを持っていますし、賢いクライアントであれば遅延は低く押さえられます。
巨大なクラスタであれば、複数のノードに対する多くのコネクションを保持しようとしますので、Redisクライアントオブジェクトを共有すべきです。
再シャーディング¶
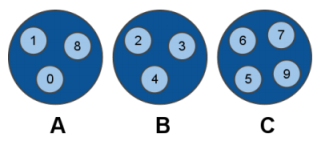
負荷が高くなってきたので、新しいサーバを追加したとします。ノードCは自分が持っているスロット7に「Dに移動」というマークを付けます。
Cノードに対して、スロット7要求するアクセスがあった場合、そのキーがCにあった場合にはそれを使って応答します。ない場合には、 -ASK D という返信をします。
-ASK は -MOVED と似ていますが、クライアントは次のDノードに対して再度クエリーを送信しなおす必要があるという点が異なります。この場合、賢いクライアントは内部のマッピングテーブルの状態を更新する必要はありません。
データの移動¶
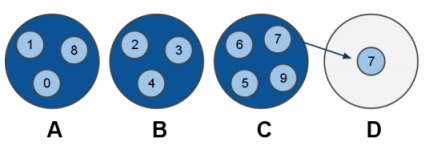
ノードDに、スロット7に関する新しいキーがすべて作られ、内容が更新されます。
redis-tribの MIGRATE コマンドを使い、Cの中の古いキーはすべてDに移動します。
MIGRATE はアトミックなコマンドで、CからDにキーを転送し、Dからデータが取得できるようになると、C内部に保存されたキーを削除します。データがおかしくなることはありません。
停止ノードに対する再シャーディング¶
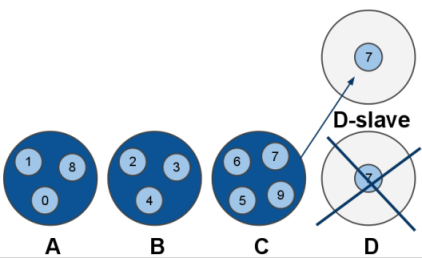
シャーディング中のノードを終了させることができます。スレーブに対して行われることがよくあります。
システム管理者は redis-trib ユーティリティを使用することがあります。何か問題があると、終了して警告を出します。この場合は再シャーディングを行う前に、クラスタの設定値をチェックしてください。
耐障害性¶
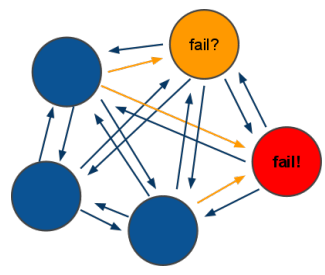
すべてのノードは、他のノードに対して、継続的にpingを送信します。指定された秒数以上の時間タイムアウトしたら、ノードはそのノードについて失敗したというマークを付けることがあります。すべてのPING/PONGパケットには、gossip(うわさ話)に関するセクションがあり、他のノードのアイドル時間など、送信ノードの観点の情報が含まれます。
ノード停止時の処理¶
Aノードがpingを送信したところ、Bに対して最後に送ったPINGがタイムアウトして、Bが停止していると推測したとします。ただ、この状態ではまだAは何もアクションを起こしません。他のヒントが得られて確証が得られるまではなにもしません。
CのノードがAに対してPONGを送信しました。PONGの中にはGossip(噂)情報も含まれています。Cもまた、Bが停止しているのではないか、と考えているという情報がこの中にあったとしします。この時点で、AはBが停止したものと判断し、この情報をクラスタ内の他のすべてのノードに送信し、クラスタ全体で、このノードが停止したという情報を共有します。
もしBが戻ってきて、Bがクラスタ内のどれらのノードにPINGを最初に送信すると、自分が早くシャットダウンすべきノードであることを知ります。
クラッシュした後にRedisのクラスタに再度加わるには、 redis-trib コマンドを使ってマニュアルで行う必要があります。
Redis-trib - Redisクラスタマネージャ¶
このコマンドは、新しいクラスタのセットアップを行う時に使用します。
このコマンドは、クラスタの構成が、設定通りになっているかどうかチェックするのに使用されます。クラスタが維持できない場合、シングルノードではなく、ハッシュスロットを持つように修正を行います。
このコマンドは、クラスタに新しいノードを追加するのにも使用できます。ノードは、既存のマスターのスレーブにもできますし、新しいブランクノードにして、他のノードの負荷を下げるために再シャーディングさせることもできます。
より複雑な情報¶
20分のプレゼンテーションに収まらないような多くの詳細情報がまだまだあります。
PING/PONGのパケットの中には、クラスタの再起動に必要な情報が含まれていますが、管理者が明示的に CLUSTER MEET コマンドを使い、IPの変更などを行えるようになっています。
すべてのノードはユニークなIDと、クラスタ設定ファイルを持っています。設定が変更されるたびに、クラスタコンフィグファイルが保存されます。
クラスタの設定ファイルは、人が手で作ることはできません。
ノードに対するIDは変更することはできません。